AWS Lambda 병렬 처리를 통한 PDF to Image 변환 삽질기

이 글은 7월에 있었던 AWSKRUG Serverless 발표때 사용한 내용입니다.
주의! 이 글은 삽질의 경험이 녹아든 글입니다. 필요하신 정보가 다 담겨있지 않을 수 있습니다.
회사에서 PDF로 나온 교재를 이미지로 변환해야하는 일이 있었는데요. 시중에 있는 툴은 모두 한 페이지씩 변환하기 때문에 오래걸리더라구요. 한 페이지에 대략 10~15초 정도가 걸렸기 때문에 100 페이지 이상 이루어지는 교재의 경우 권당 15분 이상씩 걸리는 경우가 허다했습니다.
(10+@)초 + N페이지 = 파일당 변환 시간
파일당 변환시간 + 변환 요청 파일 수
특히 나중에 도입될 변환 서비스에서 너무 과한 시간이 걸릴 것으로 판단해서 병렬처리를 도입하려고 하였습니다. 그런데 PC에서 병렬처리는 한계가 있기 때문에 AWS Lambda를 이용하기로 결정하였습니다.
작업을 시작하기 전에 했던 고민들이 있었는데요. 첫번째는 어떤 Program Language를 사용할까 하는 것이었습니다. Lambda에서 실행할 것이었기 때문에 Lambda에서 운영되는 언어중에 골랐어야 했습니다.
후보로 있었던 언어는
- 파이썬
- Javascript
- Java
- C#
제가 파이썬을 자주 사용하고 오랫동안 좋아하는 언어였기 때문에 처음엔 파이썬을 사용하려고 했습니다. 그런데 회사에서 작업을 Node.js로 구성하고 있고 요즘 작업 대부분을 Node.js 환경에서 하다보니 Node.js로 시작하는게 좋겠다 싶어서 Javascript로 처음엔 시작했습니다.
2. 삽을 들다
Javascript에서 PDF 렌더링을 Mozilla에서 만든 pdf.js를 이용했습니다. 이 pdf.js는 canvas에 의존적인데요. node에서는 canvas가 없기 때문에 canvas-node 를 설치해야합니다. Lambda에서 설치하기 위한 방법은 이 가이드에 잘 나와있습니다. canvas-node의 경우 Binary file로 되어있습니다. Lambda에 사용자 환경을 구성하기 위해서는 EC2에서 AMI(Amazon Machine Image) 환경을 구성하고 Lambda로 배포해야합니다. 그래서 가이드에 나온대로 진행하고 예제 소스를 사용했습니다. Lambda에서 작동해야하기 때문에 Local환경에서는 테스트하지 않고 바로 Lambda에 소스를 올렸습니다.
/**
* 이 예제는 가이드에 나와있는 것과 동일한 예제입니다.
* 저는 이 소스를 serverless framework 환경에 맞춰서 수정하였습니다.
*/
let {createCanvas} = require("canvas");
function hello(event, context, callback) {
let
canvas = createCanvas(200, 200),
ctx = canvas.getContext('2d');
// Write "Awesome!"
ctx.font = '30px Impact';
ctx.rotate(0.1);
ctx.fillText('Awesome!', 50, 100);
// Draw line under text
let
text = ctx.measureText('Awesome!');
ctx.strokeStyle = 'rgba(0,0,0,0.5)';
ctx.beginPath();
ctx.lineTo(50, 102);
ctx.lineTo(50 + text.width, 102);
ctx.stroke();
callback(null, '<img src="' + canvas.toDataURL() + '" />');
}
module.exports = {hello};
예제는 잘 실행되었습니다. 변환속도도 괜찮고 맘에 들었습니다. 이거면 되겠다 싶어서 �소스를 수정하기 시작했습니다. 예제를 조금 수정해서 한글 텍스트를 써서 작성하고 실행했습니다. 그런데 그때 예상치 못한 문제를 만났습니다.
3. 예상치 못한 문제를 만나다
테스트용 소스는 충격적이게도 한글 텍스트를 제대로 인식하지 못하고 글자가 깨져서 안나왔습니다. 문제를 해결해보려고 여러 방법을 시도해봤는데요.
- 인코딩 문제
- 한글 폰트 문제
- 시스템 언어 문제
먼저, 인코딩 문제의 경우 EUC-KR(윈도우에서의 한글 인코딩), UTF-8 등 한글 지원 인코딩을 적용해봐도 해결되지 않았습니다. 그래서 두번째로 한글 폰트 문제를 해결해보려고 오랜시간 삽질 끝에 한글 폰트를 넣고 실행해봤습니다만 문제는 마찬가지였습니다. 제가 모르는 방법으로 해결 방법이 있었겠지만 저는 그 방법을 찾지 못했습니다. 결국 오랜시간의 삽질에도 불구하고 그래서 과감하게 미련없이 다른 언어의 다른 방법으로 환승했습니다.
4. 도와줘요 Adobe!
결국, 다른 남은 언어 중에서 Python, Java의 선택지를 생각하면서 알아보다가 Python에서 PDF Rendering Library 중 유명한 것이 Poppler입니다. 그런데 이 라이브러리도 Bynary file에 의존적이었습니다. 반면에 Java에서 사용하는 라이브러리인 PDFbox는 Adobe에서 Adobe Reader를 만들때 사용한 동일한 라이브러입니다. 이 라이브러리는 OS에 최적화된 파일에 의존하지 않고 Java의 JVM 바이트 코드에서 작동하는 라이브러리만으로 구성되어 있었기 때문에 PC에서 컴파일하여 배포하면 끝나는 형태였습니다. 이미 AMI를 통해 배포하는 것에 굉~장한 귀찮음을 느끼고 있었기 때문에 저는 바로 Java로 작업을 시작하였습니다.
Adobe에서 오픈소스로 제공하는 이 PDFbox라는 라이브러리는 Adobe Reader 프로그램에서 사용하는만큼 Adobe Reader에서 정상적으로 작동하면 이 라이브러리를 사용했을 때도 작동해야 한다고 하는 문구가 매우 설득력 있었습니다.
그래서 새로운 삽을 들었습니다. Repository를 만들고 Serverless framework에서 Gradle 기반 Java Template로 프로젝트를 만들었습니다. Gradle을 통해서 PDFbox를 받고 Main Class에서 PDFbox를 load 하고 Lambda 이벤트를 받으면 이벤트에 있는 S3 주소를 받아서 그 위치에 변환된 Image 파일을 저장하도록 만들고 첫 페이지를 변환했습니다. 중간에 여러번의 삽질이 있었지만 결국 성공했습니다. 영문 페이지도 한글 페이지도 성공적으로 변환되었습니다. 이미지 등도 잘 변환되었구요. 이때 엄청 환호성을 질렀습니다. 글로는 간략하게 설명됬었지만 2~3일 정도 고생했거든요.
5. 병렬처리 시작
꽤 오랜시간 고생했지만 아직 본래 하려던 내용은 시작도 못했습니다. 애초에 목적은 변환이 아니라 병렬처리였으니까요. 그래서 소스를 병렬로 처리하기 위해서 작업을 시작했습니다. 병렬로 변환하게 만드는 소스를 짜기까지는 오래 걸리지 않았습니다. 애초에 잘 작동하는 소스로 Lambda를 비동기로 병렬 Invoke하고 취합해서 저장하고 결과를 돌려주면 되었으니까요.
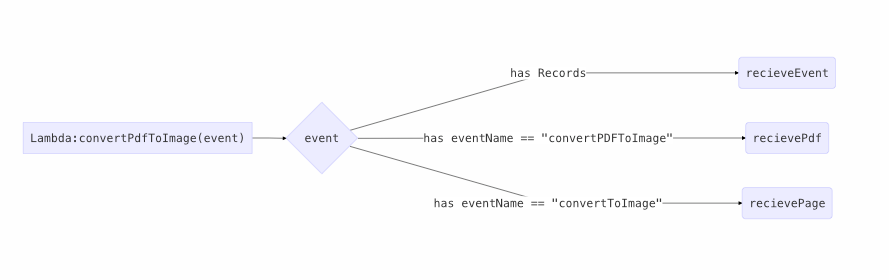
Lambda의 함수 내에서 분기를 만들어줬습니다. 큰 의미없이 함수를 여러개 만드는건 관리도 불편하더라구요. 함수를 만들때 S3 Event가 발생할 것도 고려하여 작성했습니다. 특정 경로는 자동 변환되고 User마다 올리는 변환에는 수동으로 실행하도록 하였습니다.(다 되었는지 확인하는 Response가 있기 때문에)
Lambda FlowGraph
recievePage3EvnetTrigger FlowChart
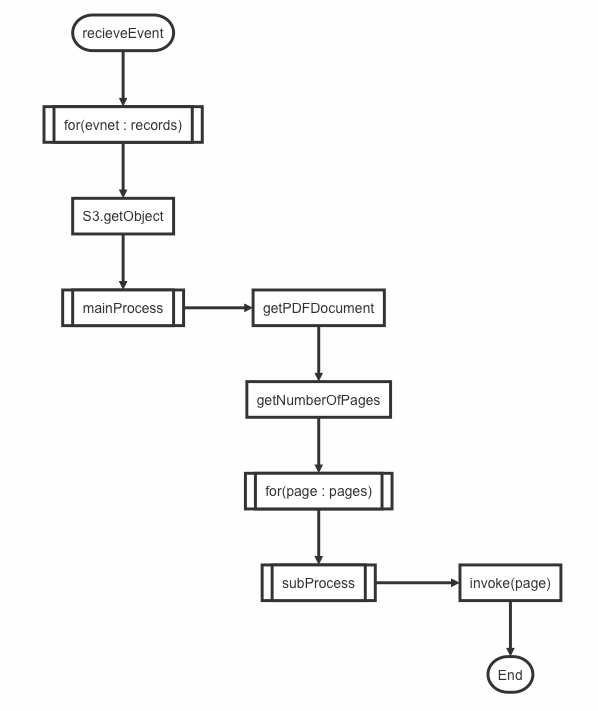
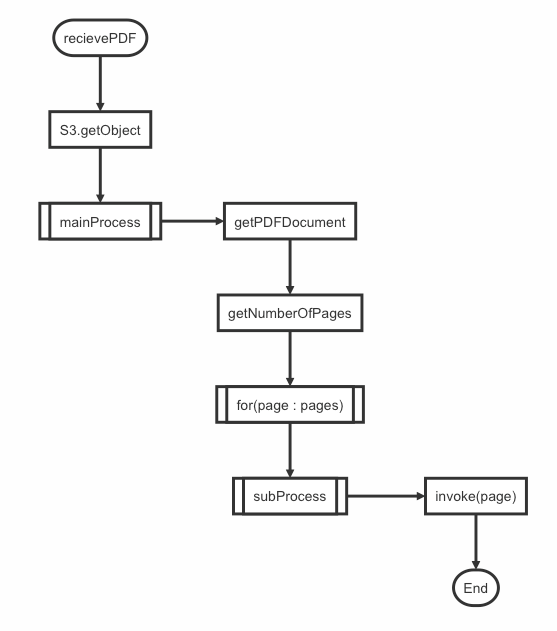
6. 결과와 문제점
자, 이제 프로그램은 완성되었습니다. 길고 긴 시간이 걸렸습니다만 소스는 무사히 완성되었네요. 실행방법은 두가지입니다.
- S3에 이벤트가 발생할수 있는 경로에 PDF파일을 업로드
- S3에 PDF파일을 업로드하고 Lambda를 Invoke
변환되어 저장된 페이지의 이미지 파일 이름을 알아야하기 때문에 저는 페이지별로 경로를 모은 index 정보가 담긴 json파일도 저장했습니다. 애초에 파일당 수십분씩 걸리던 PDF 변환이 30초 안에 끝나는 마법을 보면서 혼자 피식피식 했습니다. 하지만 사용하면서 몇가지 문제점도 있었는데요.
- 람다 동시성 예약 1000건
- 특수한 글자 인식 오류
시도해보면 좋았을 것들
- Python
- AWS SQS(Simple Queue Service)
- 엄격한 권한 관리
7. Demo
이 Repository에서 해당 소스를 가져올수 있습니다. 맘에 드신다면 별⭐️도 췍췍!